
站点启用CDN后,发现CDN日志中大部分的HTTP状态码为403,自己访问站点时,也经常会遇到站点无法打开,服务器返回HTTP状态码403的问题。如你的站点在启用CDN后也遇到以上问题,可参考以下方法分析解决:
1、检查CDN的加速域名是否可以访问源站,可以通过修改本地host文件的方式指定访问源站IP(如源站IP为192.168.1.1)。操作步骤如下:文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
1.1 打开本地的hosts文件,路径如下:C:\Windows\System32\drivers\etc\hosts文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
1.2 修改hosts文件内容,增加一条记录形如:192.168.1.1 www.abc.com 的记录在host文件下方并保存。文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
2、验证相同CDN加速的URL,访问源站是否也是403。文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
2.1 如果源站访问结果也是403,则说明CDN返回403是正确的,请继续分析是否是源站环境设置问题。文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
2.2 如果源站访问结果不是403,则检查CDN的防盗链配置。具体如下(以阿里云CDN为例):文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
白名单:只允许白名单内的referer和空referer访问,配置信息见下图:文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
 文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
黑名单:不允许黑名单内的referer访问,配置信息见下图:文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
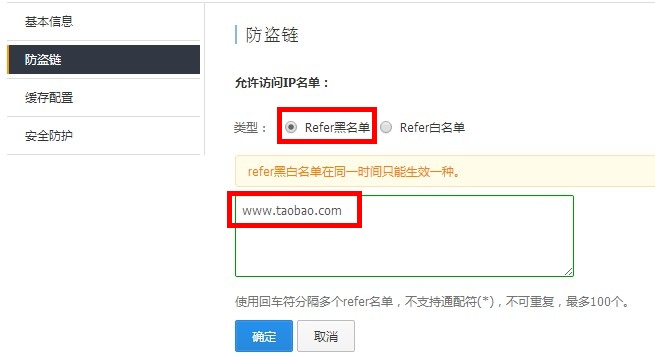 文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
文章源自堕落的鱼-https://www.duoluodeyu.com/2223.html
如你不清楚CDN防盗链设置方法,你可以清空referer白名单和referer黑名单(相当于关闭了CDN防盗链功能)。而启用CDN后访问日志出现大量的403错误状态码或者直接访问站点服务器返回403错误状态码,一般情况下都是由于防盗链设置不当造成的。
延伸阅读:









1F
这个不知有什么用。反正我如果不打勾那个R空,就403报错。那个汗。。。
Ps:网站不错。